In this paper, entitled "Faster and Accurate Compressed Video Action Recognition Straight from the Frequency Domain", we present a deep neural network for human action recognition able to learn straight from compressed video. Our network is a two-stream CNN integrating both frequency (i.e., transform coefficients) and temporal (i.e., motion vectors) information, which can be extracted by parsing and entropy decoding the stream of encoded video data.
The starting point for our proposal is the CoViAR [1] approach. In essence, CoViAR extends TSN [2] to exploit three information available in MPEG-4 compressed streams: (1) RGB images encoded in I-frames , (2) motion vectors, and (3) residuals encoded in P-frames. Although CoViAR has been designed to operate with video data in the compressed domain, it still demands a preliminary decoding step, since the frequency domain representation (i.e., DCT coefficients) used to encode the pictures in I-frames and the residuals in P-frames needs to be decoded to the spatial domain (i.e., RGB pixel values) before being fed to the network.
Roughly speaking, our approach extends CoViAR to take advantage of the ResNet-50 network modified by Santos et al. [3], enabling it to operate directly on the frequency domain, speeding up the processing time. For this reason, we named our approach as Fast-CoViAR (Fast Compressed Video Action Recognition). The similarities and differences of CoViAR and Fast-CoViAR can be observed below.
|
(a) CoViAR |
(b) Fast-CoViAR |
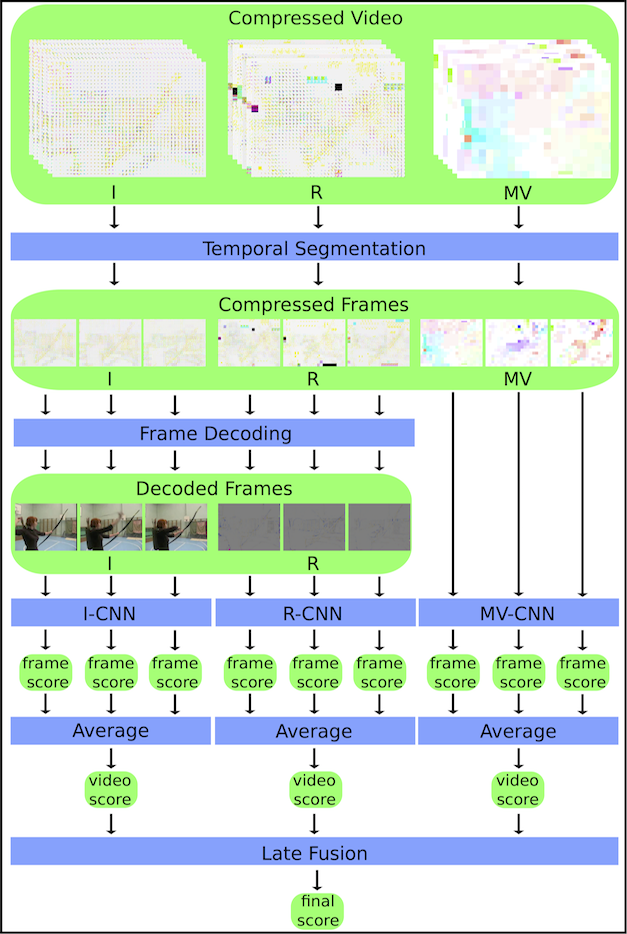
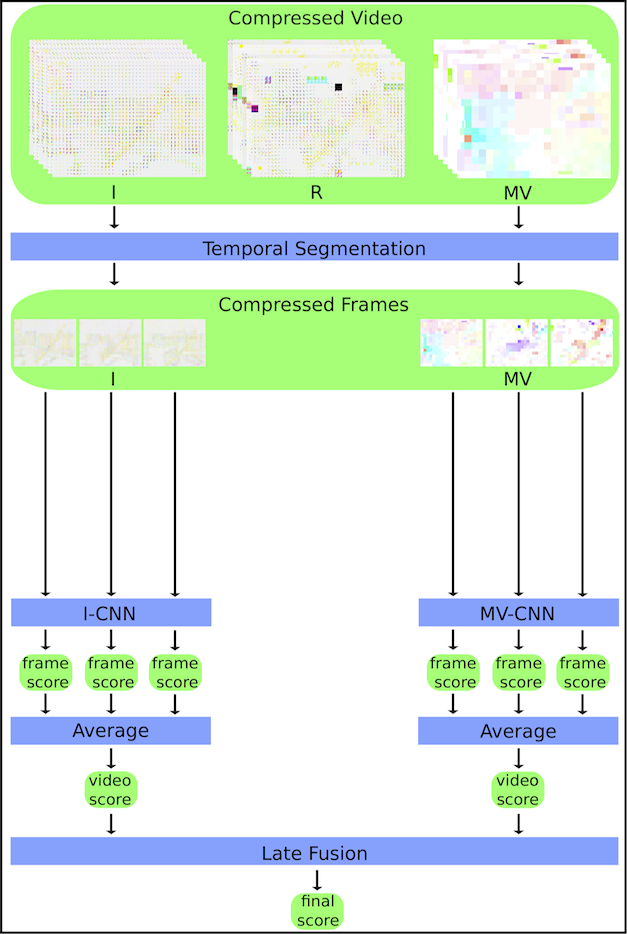
Our approach was evaluated on two public benchmarks, the UCF-101 and HMDB-51 datasets, demonstrating comparable recognition performance to the state-of-the-art methods, with the advantage of running up to 2 times faster in terms of inference speed.
This paper will be presented at the virtual 2020 SIBGRAPI - Conference on Graphics, Patterns and Images, 07-10 November!
[1] C.-Y. Wu, M. Zaheer, H. Hu, R. Manmatha, A. J. Smola, and P. Krähenbühl, “Compressed Video Action Recognition,” in IEEE International Conference on Computer Vision and Pattern Recognition (CVPR’18), 2018, pp. 6026–6035.
[2] L. Wang, Y. Xiong, Z. Wang, Y. Qiao, D. Lin, X. Tang, and L. V. Gool,“Temporal Segment Networks: Towards Good Practices for Deep Action Recognition,” in European Conference on Computer Vision (ECCV’16), 2016, pp. 20–36
[3] S. F. Santos, N. Sebe, and J. Almeida. "The Good, the Bad, and the Ugly: Neural Networks Straight from JPEG", in IEEE International Conference on Image Processing (ICIP'20), 2020, pp. 1-5.
S. F. Santos and J. Almeida. "Faster and Accurate Compressed Video Action Recognition Straight from the Frequency Domain", in SIBGRAPI - Conference on Graphics, Patterns and Images (SIBGRAPI'20), 2020, pp. 1-7.